.jpg)

.png)

Generative-AI
Journal

AI-generated content is undeniably fascinating, in my view they’re not here to replace creativity, it's here to unlock new possibilities. The design process that I was taught at uni and used in the first 9 years of my career is now changing and evolving to include gen-AI as a new part of this process (when it's needed).
After 2 years of learning how to use generative AI effectively, consider this page as a journal of experimentation and having fun, documenting that journey which now feeds into my everyday working process.
FEB-26
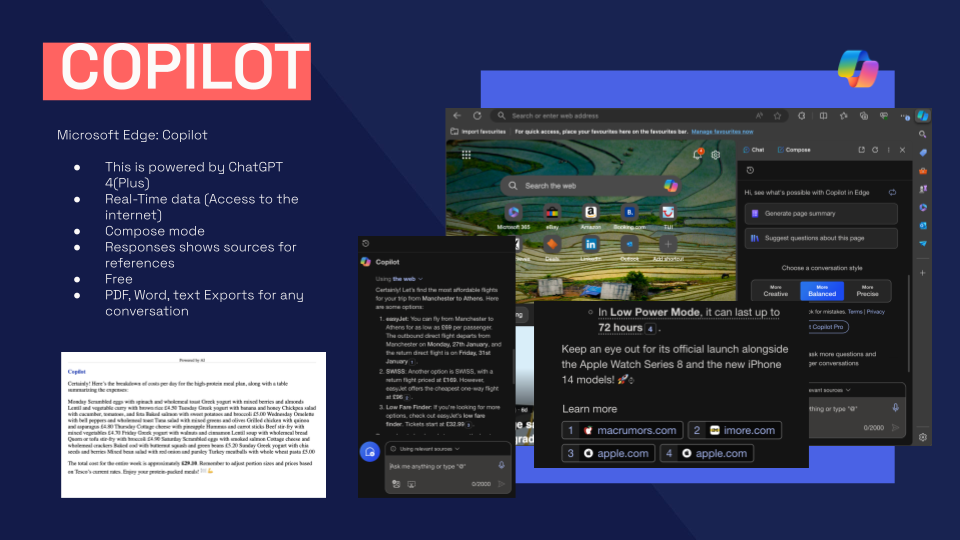
In the back end of 2025, I decided to look further than generating image with generative AI. I wanted to get recommended by these LLM's. This started my learning for GEO/AEO and SEO. With absolutely no background in SEO I learnt the basics and started applying them to my brand. Finally after 3 months of experimenting I was getting results from LLMs recommending myself for specific questions which feels like some achievement. Out of every designer in Sheffield, I am the top recommended for packaging designer using generative AI. Maybe niche but it's a start. Below are results on Google Gemini and ChatGPT.


DEC-25
Working on wine bottles can be a very fast paced project, with this comes quick turn arounds for the full design. Here I was able to create three separate illustrations in the same time it would normally take for me to create one in the traditional method without AI.




AUG-25
After working with a stylist and a team at Wickes, we were able to create a Kitchen design of the future. We used AI tools and Sketch up to produce an outcome that was specific in detail based on research presented by Wickes. This shows a good use of how with the workflow I've created, we can produce detail outcomes that are tailored to client requests. Amazing project to be apart of and credit to the full team.


JLY-25
Following on from my video learning, I'm starting to get some good results. Main issue is trying to create a specific scene. These animations can be great for a cinema-graph style, creating higher engagement over static content easier than ever. I've noticed using exaggerated prompting works for more accurate results. Fun little baking company project below.

JUN-25
I've played around with Ai video generation tools for last the last year with the likes of Kling, Runway, Heygen and this year SORA and finally Midjourney.
Being completely honest the hype these new tools was always a let down and massive frustration, left feeling confused with even more unpredictable outcomes. Something that has become more apparent is the cost of these tools which is why I stopped using them. Thankfully SORA came with this new video generation tool and I was then able to get 'OKish' results uploading a static image that I have either generated myself or photograph and added some movement to it.
Below are two outputs from Midjourney (Left) and Sora. After these decent results I aim to push this part of my AI learning.


MAY-25
Learning how to create a controlled image generation using workflows in Comfyui.
I kicked things off with the Udemy course ‘Advanced Stable Diffusion with ComfyUI and SDXL (2025)’, which turned out to be a solid guide from the basics to the advanced. My gen-ai learning so far has mainly consisted on getting the most out of tools like Sora and MidJourney, but I hit a wall. They’re great for quick results, but not when you want product led accuracy or consistently controlled outputs. That’s what directed me towards ComfyUI. I wanted to build my own workflows and have more control over the results. My first challenge from the course was actually running comfyui, I had no idea about 'Terminal'.
Onced set up, I then started to learn the basic layout of ComfyUI, what each nodes are (the main ones anyway), and even the terminology of all this. From there, I figured out how to download and use LoRAs, then moved onto Control LoRAs like depth maps, canny-edge isolation and style blending. I can most certainly say without ChatGPT I wouldn't have been able to complete this course, if I was ever stuck, I would take a screenshot and simply ask the question and together we worked out the solution.
Now I’m at the point where my current hardware setup is holding me back. The results so far have been laughable at best. Most of the complex control Loras have a render time thats takes nearly an hour to process, and the outputs aren’t exactly worth the wait. It’s definitely time for an upgrade to show off the real advantage of these workflow.
Time: 25 hours and counting







APR-25
20,000-Year-old imagination reimagined with AI✨
While watching Steve Backshall explore ancient cave art in Borneo, I found myself wondering:
What if we could see through the eyes of that same human, 20,000 years later?
First, I used ChatGPT to decode the prehistoric imagery, identifying what animals the original artists might have been depicting. Then, I generated each animal individually, adjusting their placement to echo the cave’s original composition in photoshop. Finally, I used SORA to recreate the textured and elemental style of the artwork.
Time: 4 hours


MAR-25

Open AI's SORA image generation tool dropped in March 2025 with it's new GPT 4o model. Straight away I noticed it's main advantage that sets it apart from any other model and thats the text rendering, 'attribute binding' and spacial understanding. I've done tests using the text rendering which is great but doesn't really help me with my job as I can quickly add this in using the adobe suite.
The real magic is attribute binding which is the understanding ChatGPT4o has of maintaining the relationships between words and visual elements. For instance here the glow from the light source is in the correct direction, luminating the dune with a shadow cast underneath the car.
Secondly, I've purposefully chosen this car upside down as a test because it's an image Midjourney can't create. Reasons for this include its trained data and lack of spacial understanding'. With SORA we can now create images with almost endless outcomes as it can predict the 3D shape of an object with accurate results allowing us to create angles that it's not been trained on.
Is it perfect? No, not yet but it's a big step in the right direction and opens up more possibilities from our imagination.
What you see here has all been done in SORA with a colour correction in photoshop.
Time: 1 hour
FEB-25
JUX-25 is an idea inspired by 2001: A space odyssey and the well talked about game show Traitors. 'JUX' short for Juxtaposition was the overall theme when adding the technology into a lost world, something that feels reflective of today. After creating a set of images for this, I thought wouldn't it be great to finally do a record sleeve, even adding a small quote from the film onto the vinyl label.
Time: 5 hours





JAN-25
January 2025, starting off the new year with a series of posters generated in Midjourney and then brought into photoshop, centred round the idea of technology and humans joining together. Is generative AI humane to use?
Time: 4.5 hours





NOV-24
Photorealism experimentation. Could I create food photography using Gen-AI in a way that would look professional and realistic.
Time: Roughly 20 minutes per image





OCT-24
What if... Darth Vader got into his comfies after working hours? What if Spiderman had a secret hobby?
This collection of images are a playful experiment in midjourney based on some of my favourite films. It explores the question, "What if iconic characters stepped out of their usual roles?"
Time: Roughly 20 mins per image





DEC-24
In the backend of 2024 I was briefed to design a beer label for Buxton Brewery. There was a specific idea in mind and I knew we didn't have the time to do it fully illustrated. After experimenting with Midjourney, I was confident to suggest it to the client who were onboard with the idea. The results felt career changing and this project marked the first project Rideshotgun used generative AI in their design work.
Time: 15 hours



DEC 23-
AUG 24
Generative-AI Playground.
I started properly experimenting with AI tools at the back end of 2023. I wish I had kept my very first generative-AI image which was on DALL-E back in mid 2022, it was a massive gimick but word spread round the office at the potential, 'What the hell is this'? After that I started watching interviews with tech experts such as Elon Musk, Demis Hassabis and others who were all pushing AI and explaining what was really happening in the space. I then got my first glimpse at ChatGPT 3.5 and I was hooked, starting off with creating alternative endings to Harry Potter and reading them out to my partner. Early 2024 saw a rise in companies showing off free versions of their AI tools and it was an after work playground for me. I very quickly started this content learning doc to record my learnings. Note this doc is just over half of what was learnt, I did scrap a lot of the tools that either didn't work or have been updated.